The next major AI battleground may not be the datacenter. It may be the smartphone in your pocket.
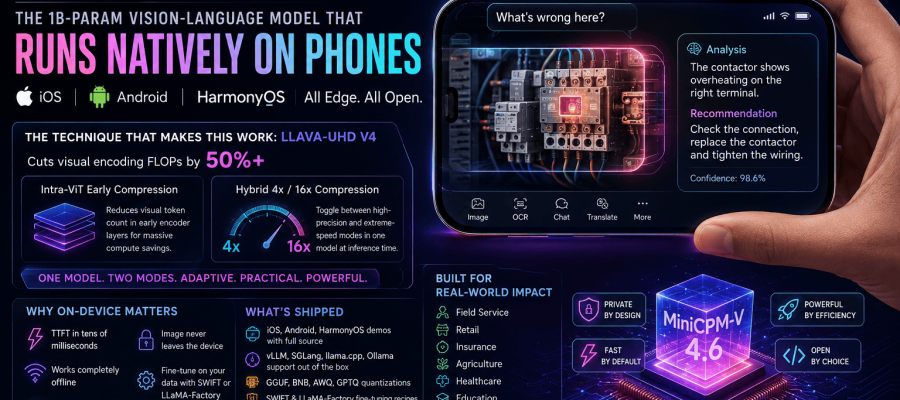
OpenBMB has released MiniCPM-V 4.6, a compact yet highly optimized 1B-parameter vision-language model (VLM) designed to run natively on mobile devices. Unlike most multimodal AI systems that depend heavily on cloud infrastructure, MiniCPM-V 4.6 executes directly on iPhones, Android devices, and HarmonyOS ecosystems — with fully open-sourced edge deployment code under the Apache-2.0 license.
At first glance, the model’s headline number — just 1 billion parameters — appears modest in an era dominated by trillion-parameter AI narratives. But the real breakthrough is not model size. It is the efficiency curve.
This release signals a broader shift in AI architecture: moving multimodal reasoning from centralized GPU clusters to edge-native intelligence running locally, privately, and in real time.
The Real Bottleneck Was Never Text — It Was Vision
For years, the biggest computational burden in mobile VLMs has not been language generation. It has been visual encoding.
Every image processed by a vision-language model gets converted into thousands of visual tokens before the LLM can reason over them. On edge devices, this becomes brutally expensive in terms of:
- FLOPs
- Memory bandwidth
- Battery consumption
- Thermal throttling
- Latency
OpenBMB’s answer is a new architecture optimization pipeline called LLaVA-UHD v4.
The innovation introduces a radically more efficient visual token compression strategy that cuts visual encoding FLOPs by more than 50%.
The optimization works through two key techniques:
1. Intra-ViT Early Compression
Instead of carrying dense visual representations deep into the transformer stack, MiniCPM compresses visual tokens aggressively during early Vision Transformer (ViT) layers.
The result:
- Lower token counts
- Faster inference
- Reduced memory pressure
- Improved mobile efficiency
This matters because mobile AI systems are fundamentally bandwidth-constrained rather than purely compute-constrained.
2. Hybrid 4× / 16× Compression Modes
This is where the engineering becomes especially practical.
MiniCPM-V 4.6 supports dual operating modes inside the same model:
4× Compression Mode
Optimized for:
- OCR
- Fine-grained analysis
- Small text recognition
- Precision inspection tasks
16× Compression Mode
Optimized for:
- General scene understanding
- Fast inference
- Lightweight interactions
- Ultra-low latency execution
The important part is that the switching happens dynamically at inference time.
One model. Two operational personalities.
That flexibility dramatically improves real-world deployment economics because enterprises no longer need separate models for precision and speed workloads.
Why Edge Vision AI Changes Enterprise Architecture
The implications go far beyond benchmark scores.
Consider industrial field service operations.
Today, if a technician needs AI assistance diagnosing faulty machinery, the workflow typically looks like this:
- Capture image
- Upload to cloud
- Wait for inference
- Receive response
- Repeat if connectivity fails
This creates multiple operational bottlenecks:
- 2–5 second latency
- Dependency on stable connectivity
- High inference API costs
- Privacy and compliance concerns
- Poor performance in remote environments
MiniCPM-V 4.6 fundamentally changes that equation.
With on-device execution:
- Time-to-first-token drops into milliseconds
- Models work fully offline
- Images never leave the device
- Per-call inference cost effectively becomes zero
- Enterprise data remains local
For regulated industries, this is critical.
A healthcare provider analyzing wound images, an insurance firm processing claim photos, or a defense contractor inspecting equipment may not legally permit sensitive imagery to leave employee devices.
Edge-native VLMs solve that problem architecturally instead of contractually.
The Rise of Mobile-First Multimodal AI
The deployment implications are enormous across industries.
Retail
- Shelf compliance
- Inventory verification
- Visual merchandising audits
Agriculture
- Crop disease identification
- Soil condition analysis
- Offline farm diagnostics
Insurance
- Real-time claim assessment
- Vehicle damage estimation
- Fraud analysis
Healthcare
- Wound monitoring
- Clinical visual assistance
- On-device medical documentation
Education
- Homework analysis
- Visual tutoring
- Interactive offline learning
Manufacturing
- Defect detection
- Machine inspection
- Assembly verification
The key pattern across all of them is identical:
AI inference moves from the cloud to the edge.
A Small Model With a Surprisingly Large Stack
Under the hood, MiniCPM-V 4.6 combines:
- SigLIP2-400M vision encoder
- Qwen3.5-0.8B language model
- LLaVA-UHD v4 optimizations
But OpenBMB’s biggest strategic advantage may actually be ecosystem openness.
The release includes:
- Apache-2.0 open-source weights
- iOS edge demos
- Android deployment demos
- HarmonyOS support
- Quantized formats:
- GGUF
- BNB
- AWQ
- GPTQ
- Native compatibility with:
- vLLM
- SGLang
- llama.cpp
- Ollama
The project also ships with:
- Fine-tuning recipes
- SWIFT integration
- LLaMA-Factory support
- Platform deployment cookbooks
That dramatically lowers the barrier for enterprises building custom edge AI products.
The Strategic Shift: AI Infrastructure Is Decentralizing
For the past two years, the AI industry narrative has centered around bigger models, larger clusters, and more GPUs.
MiniCPM-V 4.6 points in the opposite direction.
Instead of scaling upward, it scales outward.
The future may not belong exclusively to giant centralized AI systems. It may belong to billions of small, specialized multimodal models embedded directly into:
- phones
- cameras
- wearables
- industrial devices
- robotics systems
- autonomous infrastructure
This is computational decentralization happening in real time.
And as edge silicon continues improving, the distinction between “mobile app” and “AI system” may eventually disappear altogether.
The Bigger Picture
MiniCPM-V 4.6 is not merely another open-source model release.
It represents a broader transition toward:
- privacy-preserving AI
- offline-first intelligence
- low-latency multimodal reasoning
- edge-native enterprise automation
The most important AI experiences of the next decade may not happen inside browser tabs connected to hyperscale clouds.
They may happen entirely on-device — instantly, privately, and invisibly.
And that changes the economics of AI deployment everywhere.